TurboQuant KV-Cache Quantization on a Consumer-Class GPU: An Empirical Evaluation
Hazem Awadallah — Senior Systems Engineer, Kingston Technology · Independent evaluation · NVIDIA RTX A6000 · June 2026
Abstract. A transformer’s KV cache is its scratchpad: every token the model has read so far, stored as two giant tables — Keys and Values — that attention reads on every new word it predicts. The cache grows linearly with context. At 256k tokens on a 70B-class model, it can dwarf the model itself.
Google Research’s TurboQuant (arXiv:2504.19874) shrinks that cache with a two-step trick that’s easier to describe than most compressors: spin, then bucket. First, multiply every cached vector by a structured random rotation — distances and dot products stay exactly the same (rotation is an isometry), but coordinates that were “spiky” (one channel huge, the rest tiny — hard to compress) get mixed into a tidy bell-curve-with-bounds (formally a Beta distribution). Second, round each coordinate to a small set of representative values — that’s quantization, the same idea as JPEG color compression, applied per channel.
The reason this matters: TurboQuant is data-oblivious. No calibration corpus, no offline warmup, no per-model tuning; just rotate and bucket. That’s the rare quantizer you can apply to a cache that’s still growing in real time, mid-generation.
The paper reports quality neutrality at 3.5 bits per channel and only marginal degradation at 2.5 bits — about 6× compression versus the FP16 baseline. The llama.cpp TurboQuant fork exposes three value-cache tiers (turbo4, turbo3, turbo2) mapped onto that range.
We tested the fork on a single NVIDIA RTX A6000 (48 GB) across two Mixture-of-Experts (MoE) coding models — Qwen3.6-35B-A3B and Gemma-4-26B-A4B. MoE means only a fraction of the parameters fire per token (an “A3B” suffix = ~3 B active parameters), so the model fits and runs on consumer-class memory budgets despite the headline parameter count. We measured prefill and decode throughput at 32k context for all three tiers against the stock q8_0 (8-bit) baseline, then pushed decode-only on Qwen to 128k and 256k while logging peak VRAM.
The central result is counterintuitive: a smaller cache decodes faster, and the gap widens with context depth. At 256k, turbo2 hits 31.8 tok/s versus 23.1 tok/s for q8_0 — a 38% speedup. The VRAM saving on this GQA (Grouped-Query Attention) model is small (~1 GiB) because the cache is a minor fraction of resident memory. The realized benefit is memory bandwidth: every decode step reads the entire cache, a smaller cache reads in less time, and that bandwidth saving shows up directly as tokens per second.
Reproduction scripts and the raw llama-bench JSON are at github.com/hazemawadalla/turboquant.
1. Background: What TurboQuant Actually Does
The problem in one sentence. A transformer generates text one token at a time. For each new token, the attention layer compares the current query vector against every Key from earlier tokens, then takes a weighted sum of the Value vectors. Recomputing all those Keys and Values from scratch every step would be quadratic in context length, so the model caches them as it goes. That cache is the KV cache. On a 70B-class GQA model it grows by roughly 144 KB per token; at 256k it’s ~36 GiB — bigger than most checkpoints.
The cache eats two budgets: VRAM (how much you can fit) and memory bandwidth (how fast you can read it back). On modern accelerators the second budget runs out first, which is why decode is “memory-bandwidth bound” — the GPU is fast enough; the bottleneck is shuttling weights and cache through the L2 and HBM.
TurboQuant’s idea, in two moves
Move 1 — Spin (random rotation). Multiply every cached vector by a structured random orthogonal matrix. A rotation preserves both norms and dot products, so the attention math is mathematically unchanged. What it does change is the per-coordinate distribution: spiky distributions get mixed into a tidy bell-curve-with-bounds (a Beta distribution), and quantization gets dramatically easier when the values you’re trying to round look the same in every dimension.
The paper proposes a structured rotation (the Walsh-Hadamard transform is the canonical fast choice — discrete cosine’s binary cousin) that runs in O(d log d) instead of O(d²), so it can be applied inline as the cache grows without inflating prefill cost.
Move 2 — Bucket (scalar quantization). Once the values are evenly distributed, a simple scalar quantizer works well: pick K representative values (2.5 bits per channel = ~6 buckets), round each coordinate to its nearest one, and store the index. Same principle as JPEG color quantization, applied per coordinate.
The dot-product correction
There’s a subtle bit. A quantizer tuned for minimum mean-squared error (MSE) — the obvious choice for “round to the nearest value” — biases the inner product, and the inner product is exactly what attention computes. Use plain MSE quantization and you get a systematic skew in attention weights, even with no error variance.
TurboQuant fixes this with a one-bit correction term called Quantized JL (QJL), named after the Johnson-Lindenstrauss lemma — a classic probability result that says a random projection can preserve dot products with provable accuracy. One extra bit per coordinate; the bias goes away.
The theoretical guarantee
The paper proves the resulting distortion sits within a small constant factor of the information-theoretic floor for online vector quantization — meaning no other data-oblivious compressor can do dramatically better at the same bitrate. Practical translation: ~6× compression at quality neutrality, ~10× at “marginal degradation,” and attention kernels that run faster because they’re touching less data per step.
Where the llama.cpp fork plugs in
The fork exposes three value-cache tiers, selectable at runtime via --cache-type-v on the llama.cpp server:
| Tier | Bits / element | V-cache size vs q8_0 |
Use for |
|---|---|---|---|
turbo4 |
~4.5 | 0.53× | Conservative first contact with a new model |
turbo3 |
~3.5 | 0.41× | Recommended default — the paper’s quality-neutral point |
turbo2 |
~2.0 | 0.24× | Aggressive — long context and fast decode |
They sit next to the existing q8_0 (8-bit) baseline. Note turbo2 runs below the paper’s tested 2.5-bit “marginal degradation” floor, so treat it as the aggressive setting it is. The turbo* tiers are fork-only and require Flash Attention.
2. Method
Hardware. NVIDIA RTX A6000 (48 GB, sm_86), AMD Ryzen 9 3900X (12C/24T), 31 GiB RAM, Ubuntu 24.04 on WSL2.
Software. The TurboQuant fork (TheTom/llama-cpp-turboquant, branch feature/turboquant-kv-cache) built with CUDA 12.0 for sm_86.
Models. Unsloth Q4_K_M GGUFs of Qwen3.6-35B-A3B (34.7 B params, ~3 B active) and Gemma-4-26B-A4B (25.2 B, ~4 B active), both MoE with grouped-query attention.
Protocol. llama-bench drove every run; each value tier was swept back-to-back on one loaded model. We applied the asymmetric K/V rule throughout: the Key cache stays at q8_0 and only the Value cache is compressed, with Flash Attention on. Models were fully GPU-resident (-ngl 999, no expert offload). At 32k depth we used a 4096-token prefill, 128-token decode, and 3 repetitions; the 128k and 256k Qwen sweeps used a 512-token prefill, 64-token decode, and a single repetition, so treat the long-context points as indicative rather than averaged.
3. Results
3.1 Four tiers at 32k depth (both models)
| Model | Metric | q8_0 | turbo4 | turbo3 | turbo2 |
|---|---|---|---|---|---|
| Qwen3.6 | Prefill | 2140 | 2072 | 2037 | 1818 |
| Qwen3.6 | Decode | 66 | 70 | 67 | 74 |
| Gemma-4 | Prefill | 2258 | 2197 | 2116 | 2133 |
| Gemma-4 | Decode | 58 | 55 | 60 | 63 |
Table 1. Throughput (tokens/s) at 32k depth, mean of 3 reps. Prefill is compute-bound and slightly favors q8_0; decode already tilts toward the turbo tiers.
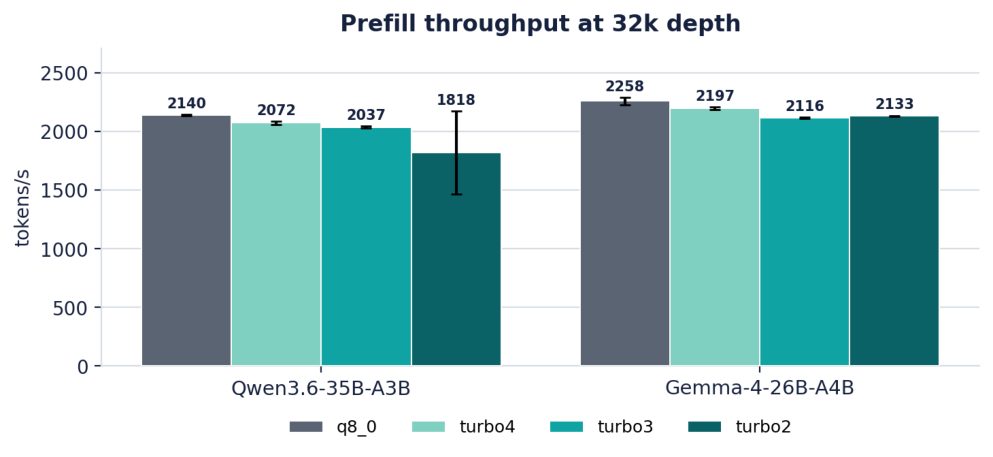
Figure 1. Prefill throughput at 32k depth.
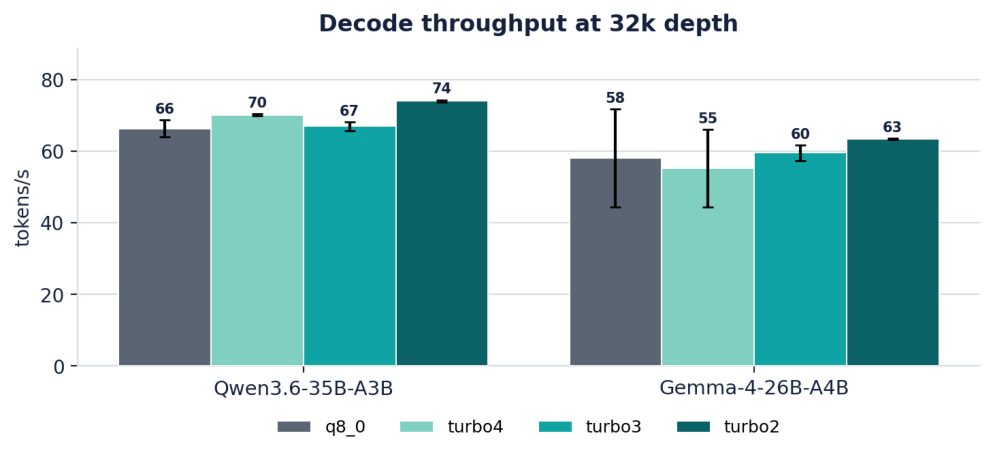
Figure 2. Decode throughput at 32k depth.
3.2 Context-length scaling on Qwen3.6 (32k to 256k)
| Depth | q8_0 | turbo3 | turbo2 |
|---|---|---|---|
| 32k | pp 2140 / tg 66 | pp 2037 / tg 67 | pp 1818 / tg 74 |
| 128k | pp 1424 / tg 38 | pp 1221 / tg 35 | pp 1316 / tg 48 |
| 256k | pp 867 / tg 23 | pp 782 / tg 25 | pp 913 / tg 32 |
| peak VRAM @ 256k | 30.4 GiB | 29.5 GiB | 29.5 GiB |
Table 2. Qwen3.6 throughput (tokens/s) by depth; pp = prefill, tg = decode (1 rep at 128k/256k). All three tiers fit at 256k on the 48 GB card.
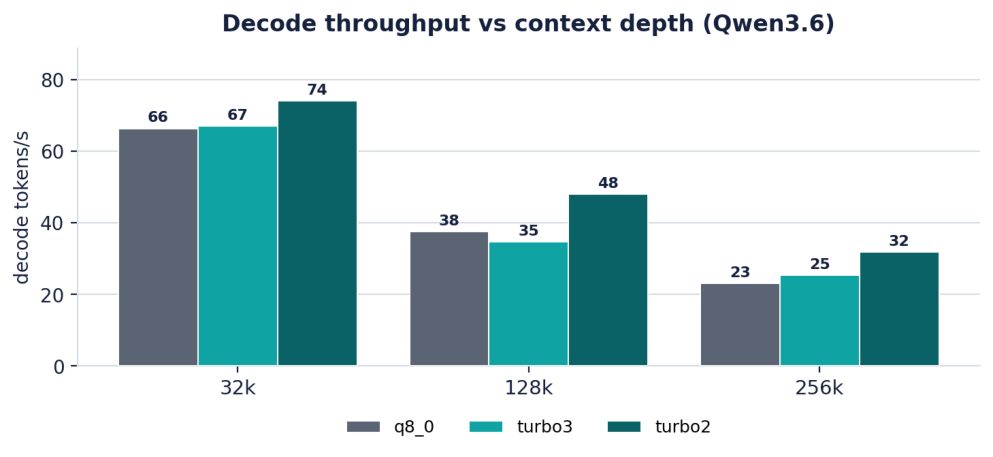
Figure 3. Decode throughput falls with depth for every tier (it is memory-bandwidth-bound), but turbo2 falls the least.
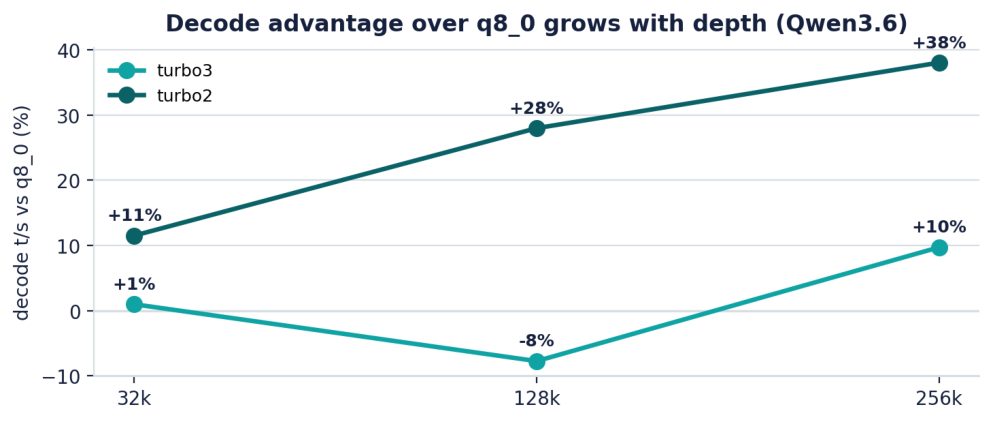
Figure 4. turbo2’s decode advantage over q8_0 grows with context depth; turbo3 stays near parity. This is the core correlation.
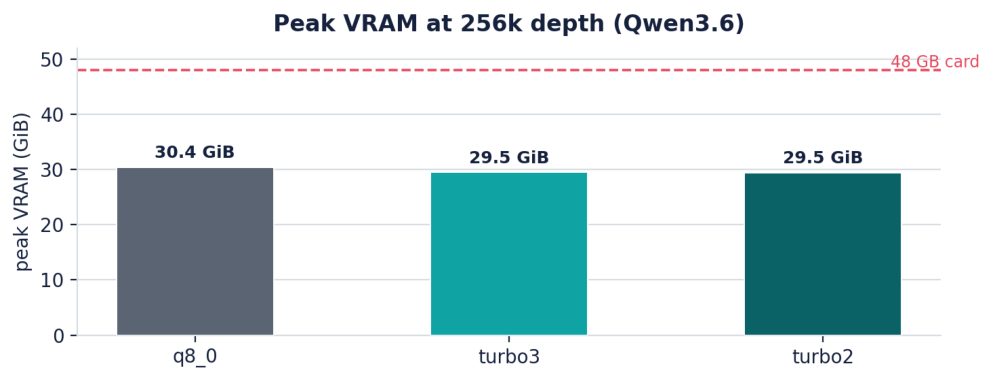
Figure 5. Measured peak VRAM at 256k. The tiers differ by about 1 GiB: this MoE’s GQA cache is a small slice of resident memory.
4. Correlation with the TurboQuant paper
Our measurements line up with the paper’s mechanism, not just its slogans. The paper argues that a smaller, rotated cache makes attention cheaper to read; in practice decode is exactly the phase that is memory-bandwidth-bound, and our decode advantage for the most aggressive tier rises from +12% at 32k → +28% at 128k → +38% at 256k. The deeper the context, the larger the cache each generated token must stream, so the tier that stores the fewest bits wins by a wider margin. Prefill, which is compute-bound, behaves as expected and gives the q8_0 baseline a small edge at shallow depth, though even prefill tilts toward turbo2 at 256k as attention reads start to dominate.
Where our result refines the headline is memory. The paper’s ~6× figure is a property of the cache itself (16-bit down to under 3 bits). On a GQA MoE model the KV cache is a small fraction of resident memory, so compressing the value half from ~8.5 to ~2 bits moved peak VRAM by only about 1 GiB at 256k (q8_0 30.4 GiB, turbo2 29.5 GiB). The compression is real; it simply lands as bandwidth rather than as large VRAM headroom on this class of model. On dense models with multi-head attention, where the KV cache is a much larger fraction of memory, the same tiers would free proportionally more VRAM.
We did not measure output quality, so we take the paper’s quality claims at face value: 3.5-bit (turbo3) as quality-neutral and 2.5-bit as marginally degraded. That positions turbo3 as the safe default and turbo2 as the tier to reach for when decode speed at long context matters more than a small quality margin.
5. Practical guidance
- Keep the Key cache at
q8_0and compress only the Value cache. Asymmetric K/V is the rule that holds quality while capturing the bandwidth win. - Use
turbo3(3.5-bit) as the default. The paper calls it quality-neutral and we saw it trackq8_0on throughput. - Reach for
turbo2on long agent sessions. Its decode lead widens with depth (+38% at 256k here), which is where per-token cost accumulates. - Expect bandwidth gains, not necessarily large VRAM savings, on GQA MoE models. On dense MHA models the VRAM headroom from compression will be larger.
6. Reproducing this
Every command below was run on the hardware in §2. Raw llama-bench JSON, peak-VRAM samples, plotting scripts, and a router for swapping between a dozen models are in the project repo: github.com/hazemawadalla/turboquant. The setup_guide.md there walks the long version; below is the minimum to land at the numbers in §3.
Prerequisites (Ubuntu / WSL)
sudo apt-get install -y nvidia-cuda-toolkit gcc-12 g++-12 cmake ninja-build git
pip install -U "huggingface_hub[cli]"
gcc-12 is intentional — Ubuntu 24.04’s default gcc-13 is too new for CUDA 12.0’s host-compiler check, so we pin the older toolchain.
Fetch the GGUFs
mkdir -p models
huggingface-cli download unsloth/Qwen3.6-35B-A3B-GGUF \
Qwen3.6-35B-A3B-UD-Q4_K_M.gguf --local-dir ./models
huggingface-cli download unsloth/gemma-4-26B-A4B-it-GGUF \
gemma-4-26B-A4B-it-UD-Q4_K_M.gguf --local-dir ./models
Build the TurboQuant fork
git clone --depth 1 -b feature/turboquant-kv-cache \
https://github.com/TheTom/llama-cpp-turboquant .llama-cpp-turboquant
cmake -S .llama-cpp-turboquant -B .llama-cpp-turboquant/build -G Ninja \
-DCMAKE_BUILD_TYPE=Release -DGGML_CUDA=ON -DLLAMA_CURL=ON \
-DCMAKE_CUDA_ARCHITECTURES=86 \
-DCMAKE_C_COMPILER=gcc-12 -DCMAKE_CXX_COMPILER=g++-12 \
-DCMAKE_CUDA_HOST_COMPILER=g++-12
cmake --build .llama-cpp-turboquant/build -j --target llama-server llama-bench
export PATH="$PWD/.llama-cpp-turboquant/build/bin:$PATH"
CMAKE_CUDA_ARCHITECTURES=86 targets Ampere (RTX A6000, RTX 3090, A100). Set 89 for Ada (RTX 4090, L40), 75 for Turing, 120 for Blackwell.
32k sweep (Table 1)
-ctk is Key cache, -ctv is Value cache. Sweep four -ctv values on the same loaded model. -fa 1 is Flash Attention; -ngl 999 keeps every layer on GPU; -r 3 averages three reps; -d 32768 sets the attention depth.
llama-bench -m ./models/Qwen3.6-35B-A3B-UD-Q4_K_M.gguf \
-ngl 999 -fa 1 \
-ctk q8_0 -ctv q8_0,turbo4,turbo3,turbo2 --mmap 0 \
-p 4096 -n 128 -d 32768 -r 3
llama-bench -m ./models/gemma-4-26B-A4B-it-UD-Q4_K_M.gguf \
-ngl 999 -fa 1 \
-ctk q8_0 -ctv q8_0,turbo4,turbo3,turbo2 --mmap 0 \
-p 4096 -n 128 -d 32768 -r 3
128k and 256k scaling on Qwen (Table 2)
Single-rep, smaller prefill so the load+warmup doesn’t dominate wall-clock. These are indicative rather than averaged.
llama-bench -m ./models/Qwen3.6-35B-A3B-UD-Q4_K_M.gguf \
-ngl 999 -fa 1 \
-ctk q8_0 -ctv q8_0,turbo3,turbo2 --mmap 0 \
-p 512 -n 64 -d 131072 -r 1
llama-bench -m ./models/Qwen3.6-35B-A3B-UD-Q4_K_M.gguf \
-ngl 999 -fa 1 \
-ctk q8_0 -ctv q8_0,turbo3,turbo2 --mmap 0 \
-p 512 -n 64 -d 262144 -r 1
Serving for interactive use
turbo3 is the safe default — quality-neutral per the paper, throughput on par with q8_0 per our measurements. Switch to turbo2 when you’re running long agent sessions and want the +38%-at-256k decode lead. The server is OpenAI-compatible on :8080.
llama-server --model ./models/Qwen3.6-35B-A3B-UD-Q4_K_M.gguf \
--no-mmap --n-gpu-layers 999 --flash-attn on \
--cache-type-k q8_0 --cache-type-v turbo3 \
--ctx-size 32768 --host 0.0.0.0 --port 8080 --jinja
Or just ./run_server.sh from the repo — it does the build, the download, and the server launch in one shot, with turbo3 as the default. If you want the per-GPU optimum for --n-cpu-moe, --ubatch-size, and the cache tier, run autotune.py first and feed the results back in.
7. Limitations
Single GPU and single quantization (Q4_K_M). Long-context points are one repetition, so the 128k and 256k figures are indicative; turbo3’s decode dipped below q8_0 at 128k, inside single-run noise. We measured throughput and VRAM, not perplexity or task accuracy, and the long-context sweep covered Qwen only.
Model files were read over WSL’s 9p filesystem, which slows load but does not affect steady-state inference. None of this changes the direction of the result; it bounds its precision.
References
[1] A. Zandieh, M. Daliri, M. Hadian, V. Mirrokni. TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate. arXiv:2504.19874, 2025 (ICLR 2026).
[2] TheTom. llama-cpp-turboquant, branch feature/turboquant-kv-cache. github.com/TheTom/llama-cpp-turboquant
[3] ggml-org/llama.cpp. TurboQuant — Extreme KV Cache Quantization. Discussion #20969.
[4] Unsloth. Qwen3.6-35B-A3B-GGUF and gemma-4-26B-A4B-it-GGUF (Hugging Face).
[5] H. Awadallah. turboquant — reproduction scripts and raw measurements. github.com/hazemawadalla/turboquant
All figures and tables generated from raw llama-bench JSON measured on the machine described in §2.